InferSight
Production-Grade GPU Observability for Heterogeneous AI Infrastructure
A unified, vendor-agnostic platform — built in Rust — that brings first-class GPU telemetry and interactive monitoring into a single, extensible toolkit.
The Problem
The AI/ML revolution has placed accelerators at the center of modern compute. Organizations operate heterogeneous fleets spanning NVIDIA GPUs, AMD GPUs, Google Cloud TPUs, and increasingly DPUs for network offload — yet accelerator observability remains one of the largest blind spots in production infrastructure.
The tooling landscape is fragmented. Every vendor ships its own incompatible CLI. There's no native Prometheus support. No terminal dashboards. No unified observability layer. And the community alternatives? Python scripts with high overhead and limited metrics.
For teams running GPU clusters at scale, this means delayed incident response, wasted compute from invisible underutilization, operational toil from manual SSH sessions, and blind capacity planning without historical metrics.
What Is InferSight
InferSight is a complete accelerator observability platform. One toolkit that unifies monitoring and metrics export across all vendors — shipping as zero-dependency static Rust binaries.
It is also an embeddable library. The core data collection and metrics logic ships as reusable Rust crates that can be integrated into any application — your custom orchestrator, your training framework, your fleet management daemon. Use it as a standalone tool or embed it directly into your infrastructure.
Three pillars. One platform:
The Interactive Terminal Dashboard
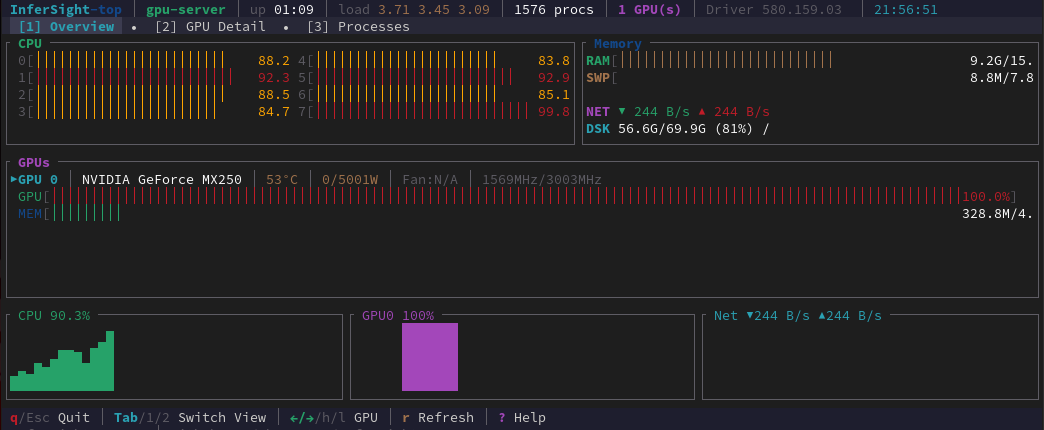
Everything at a glance. Per-core CPU utilization, RAM and swap, network throughput, disk space, GPU utilization with real-time bars, and rolling sparkline history — all in one terminal window.
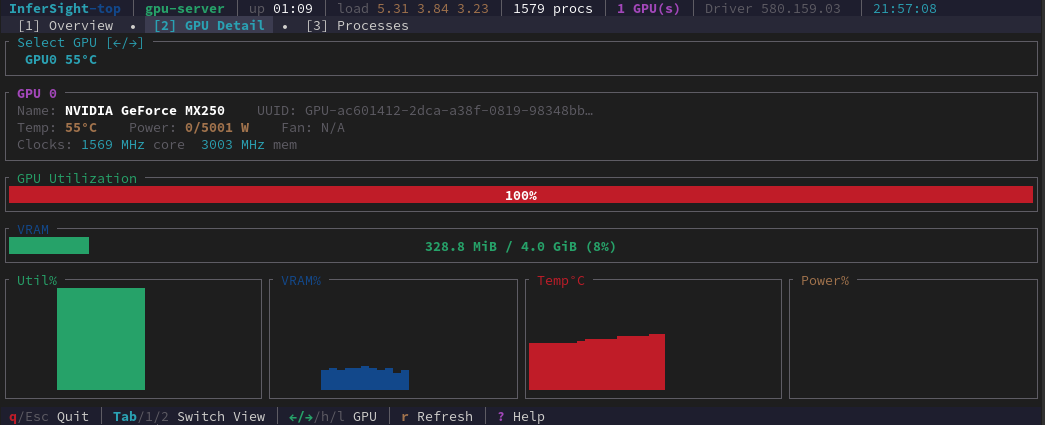
Deep-dive into any GPU. Temperature, power, VRAM, clock speeds, and 120-second rolling sparklines that make thermal events and performance regressions immediately visible.
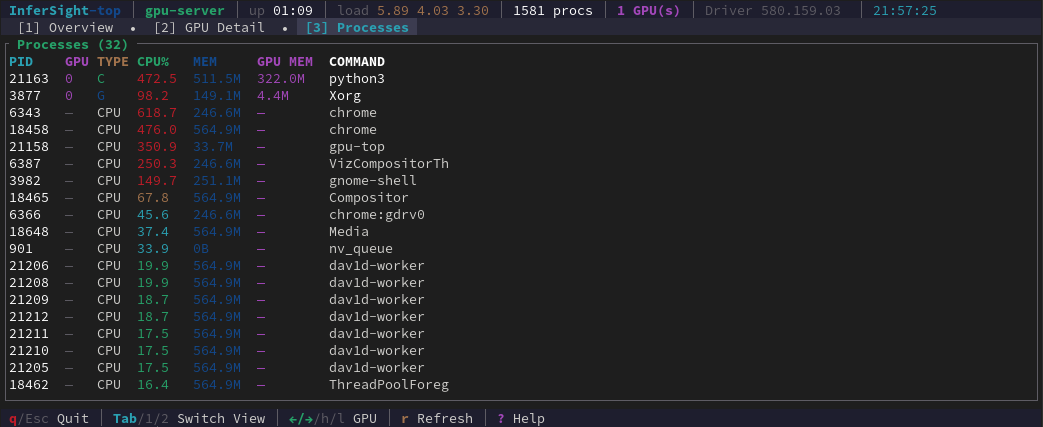
See exactly which processes are consuming your GPU. Identify runaway jobs, memory-hungry servers, or unexpected consumers — sorted by resource consumption.
The Prometheus Exporter
InferSight exposes 25+ GPU and system metrics as a production-grade Prometheus scrape target. Drop it onto any node, and your existing Grafana stack immediately gains full accelerator visibility — utilization, memory, power, thermals, clocks — all with consistent labels across vendors.
The exporter is built around an extensible Collector pattern. Today it supports NVIDIA, AMD, and TPU — with DPU support on the roadmap. Adding new hardware is trivial — implement one interface and every dashboard, alert, and visualization works automatically.
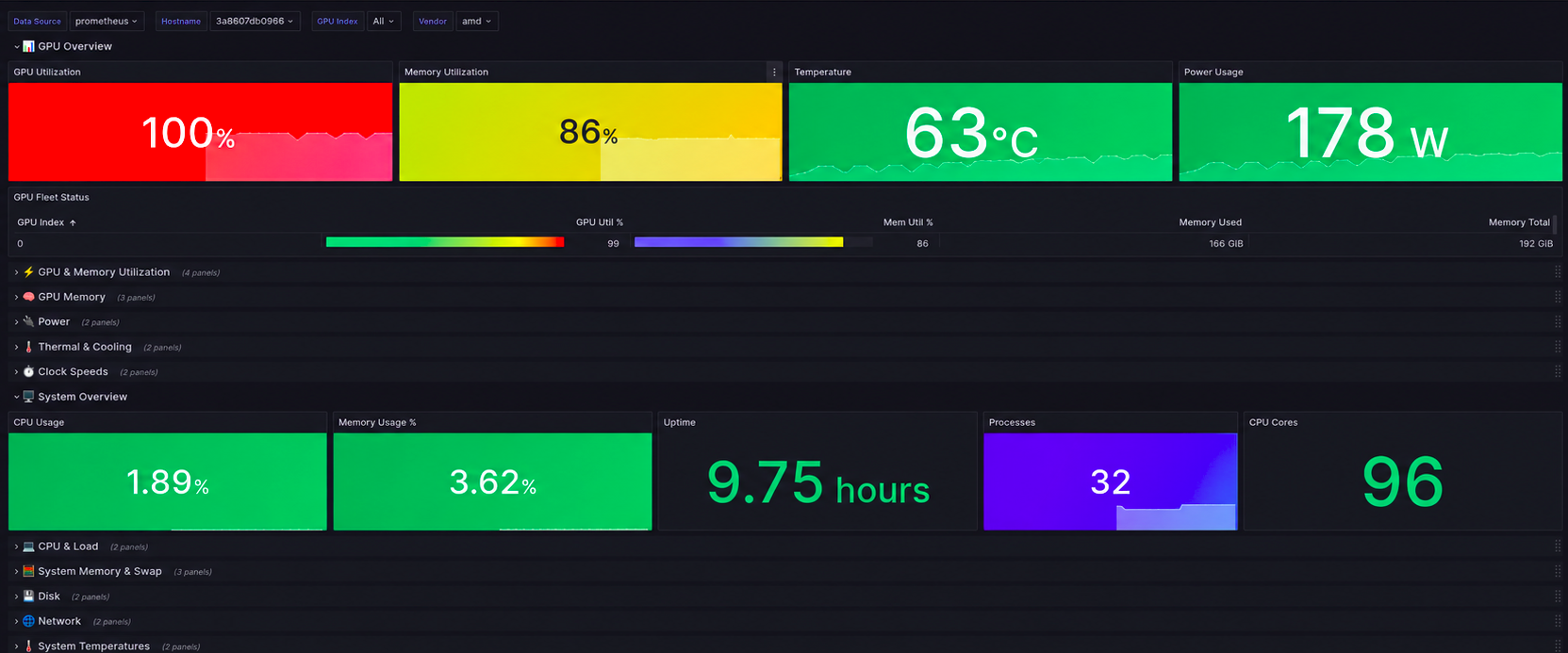
Ships with a pre-built Grafana dashboard. GPU fleet overview, per-device deep dives, system correlation panels, and template variables for filtering by hostname, GPU index, and vendor. Import the JSON and you're done.
The Local Web Dashboard
InferSight includes a built-in web UI — think cAdvisor, but for GPUs. Start the exporter and navigate to localhost:9835 to get a self-contained, real-time web dashboard with interactive graphs, without needing Grafana or any external tooling.
Perfect for development machines, single-node setups, or quick debugging sessions where spinning up a full Prometheus + Grafana stack is overkill. The same metrics, the same data, rendered as interactive charts in your browser — zero configuration, zero external dependencies.
Embeddable Library
InferSight isn't just a set of binaries — it's a library-first architecture. The core crates (is-nvidia, is-amd-ffi, is-exporter) are designed to be embedded into any Rust application:
- Custom orchestrators — embed GPU metrics collection directly into your job scheduler
- Training frameworks — add real-time GPU telemetry to your ML training loops
- Fleet daemons — integrate GPU telemetry into your existing node management agent
- CI/CD pipelines — query GPU state programmatically during build and test
Add it as a dependency, call the collector APIs, and you have production-grade GPU telemetry without running a separate process.
Why InferSight
Unified. One platform replaces nvidia-smi, rocm-smi, separate monitoring daemons, and custom scripts. Same interface regardless of vendor.
Extensible. Supports NVIDIA, AMD, and TPU today — with DPU support coming. Adding new accelerators is implementing one trait. The platform grows with your infrastructure.
Embeddable. Use it as standalone binaries or embed the library directly into your own applications. No IPC, no sidecar containers — just link and call.
Self-contained web UI. Get interactive GPU graphs at localhost:9835 without Grafana — like cAdvisor for accelerators.
Zero-config. Auto-detects available hardware at startup. Gracefully skips unavailable vendors. Works immediately with no configuration files.
Lightweight. Static Rust binaries. No Python, no Node, no containers needed. Sub-50ms startup. Under 15MB memory footprint.
Production-ready. Prometheus-native metrics, Kubernetes liveness probes, graceful shutdown, structured logging, and pre-built Grafana dashboards.